
Technique SEO
Le protocole HTTP permet à un client (votre navigateur web) et à un serveur de communiquer entre eux et de se transmettre des fichiers et informations. Les entêtes HTTP font partie intégrante de ce protocole. A quoi servent-ils ? Comment peut-on les utiliser dans le cadre du référencement naturel ? Nous vous proposons un article pour y voir plus clair sur ce sujet un peu obscur pour les néophytes.
Définition de l’en-tête HTTP
L’entête HTTP (ou header HTTP) correspond à une liste d’information, renvoyée par le serveur à client, concernant une page ou un document.
Concrètement, lorsque vous essayez de vous connecter à une page web, le serveur va vous retourner la page HTML avec ses images, ses vidéos… avec en plus des données / des informations au sujet de cette page que vous venez de charger : c’est l’entête HTTP. Parmi ces informations, on va retrouver par exemple le code d’état HTTP (200, 404, 500…), la date, le type de serveur, la date de la dernière modification du contenu, etc.
L’ensemble de ces données sont renvoyées au navigateur web par le serveur, dans l’en-tête HTTP, en plus du code HTML de la page demandée initialement par le client.
Un exemple d’en-tête :
HTTP/1.1 200 OK Date: Mon, 11 May 2020 14:10:06 GMT Server: Apache/2.4.25 (Debian) Content-Type: text/html; charset=UTF-8
Vous remarquez que la structure est la suivante : un en-tête par ligne, avec une construction du type Nom-entete: valeur
Les codes renvoyés dans l’entête HTTP
Connaître et analyser les statuts de réponse contenus dans les entêtes HTTP est un élément important pour le SEO. En effet, les moteurs de recherche vont pouvoir utiliser ces informations. Par exemple, si un document renvoie un code d’erreur 404 (page introuvable) alors les moteurs de recherche vont arrêter de proposer ces pages à leurs internautes.
Vous comprenez donc mieux pourquoi il est important d’une part que les codes HTTP renvoyés soient les bons, et d’autre part quel est l’intérêt à les contrôler régulièrement.
Les codes de statuts HTTP sont répartis en 5 grandes catégories :
- 1XX – Les codes commençant par 1 correspondent à une information
- Exemple : 100 Continue (en attente de la suite de la requête)
- 2XX – Les codes commençant par 2 correspondent à un succès
- Exemple : 200 OK (la requête du client à été traité avec succès)
- 3XX – Les codes commençant par 3 correspondent à une redirection
- Exemple : 301 Moved Permanently (la ressource demandée à été déplacée de façon permanente)
- 4XX – Les codes commençant par 4 correspondent à une erreur du côté du client
- Exemple : 404 Not found (la page ou le document demandé par le client n’a pas été trouvée)
- 5XX – Les codes commençant par 5 correspondent à une erreur du côté du serveur
- Exemple : 500 Internal Server Error (erreur interne du serveur)
De nombreux codes de réponse existent, si besoin, Wikipedia propose une liste assez exhaustive de ceux-ci.
Les principaux codes de réponses à connaitre pour le référencement naturel
En référencement naturel, vous serez confrontés à quelques codes de réponses des entête HTTP très régulièrement :
- code 200 : tout es OK
- code 302 : document déplacé de manière temporaire (redirection ne transmettant pas de popularité)
- code 301 : document déplacé de manière permanente (redirection qui transmet la popularité de l’ancienne URL à la nouvelle)
- code 307 : Redirection temporaire (vous le trouvez généralement lors d’une redirection de HTTP vers HTTPS avec le protocole HSTS)
- code 404 : Erreur, ressource non trouvée
Un trop grand nombre de redirections, d’erreurs 500 ou de pages 404 peut s’avérer pénalisant pour votre référencement. Demandez un audit technique SEO de votre site pour vous assurer que vos codes de réponses ne sont pas problématiques, ou pour mettre en place les correctifs si ce n’est pas le cas.
Comment visualiser simplement les entêtes HTTP de vos URL ?
De nombreux outils en ligne vous permettent de visualiser très simplement le contenu du header http d’une page web ou d’un document.
Nous vous recommandons par exemple :
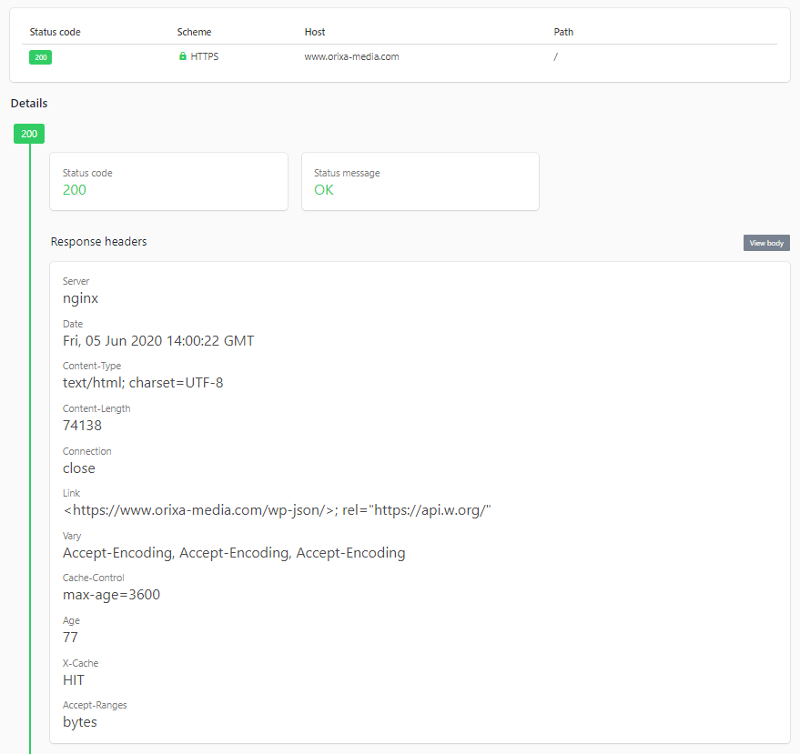
Exemple de visualisation de l’en-tête HTTP de la page d’accueil de notre site Orixa Media via l’outil Httpstatus.io
Pour analyse de grands volumes de pages, vous pouvez utiliser des crawlers tels que Screaming Frog ou OnCrawl afin d’identifier des URL qui renvoient un code HTTP particulier.
Dans l’exemple ci-dessous, nous avons utilisé Screaming Frog pour pouvoir identifier des groupes de pages en fonction du code renvoyé dans le header HTTP.
C’est l’onglet “Response Code” de notre crawler qui nous permet d’obtenir ces informations.
Le crawler va classer les pages en 4 grandes catégories : les succès, les redirections, les erreurs client et les erreurs serveur.
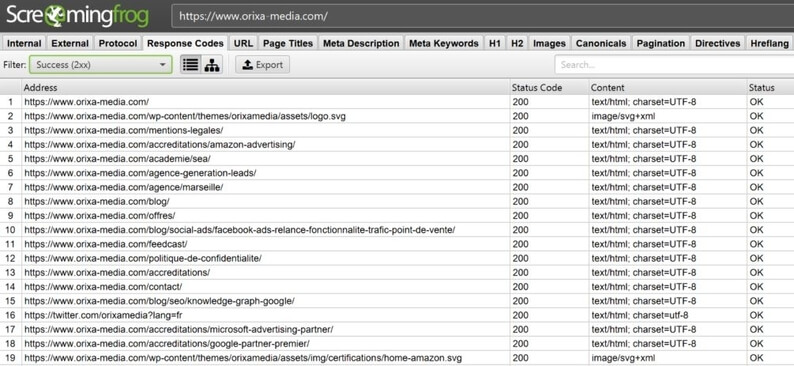
Lecture des Status Code avec Screaming Frog
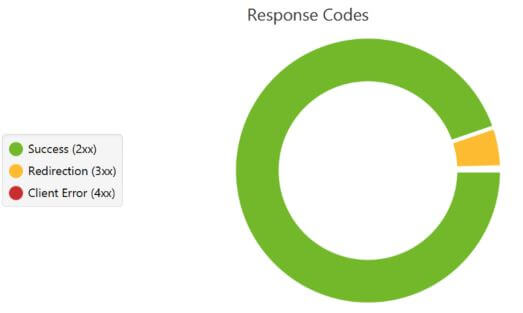
Répartition des codes HTTP pour l’ensemble des pages d’un site internet via Screaming Frog
L’utilisation de la directive X-Robots-Tag dans le header HTTP pour le SEO
La directive X-Robots-Tag permet d’ajouter des informations à destination des moteurs de recherche, directement dans l’en-tête HTTP.
Cela va être particulièrement utile pour donner des consignes aux moteurs de recherche concernant des pages non HTML, ou bien si pour une raison X ou Y nous ne pouvons pas avoir accès au code source.
Ainsi, imaginons que vous souhaitiez rendre non indexables l’ensemble des fichiers PDF ou Word d’un site internet. Grâce à la directive X-Robots-Tag, il va vous être possible d’envoyer une consigne de non-indexation aux moteurs de recherche (chose impossible à faire de manière traditionnelle avec une balise meta robots noindex, étant donné que les fichiers PDF et Word sont des documents non HTML).
Voici quelques directives X-Robots-Tag que vous pouvez utiliser dans vos entetes HTTP:
- X-Robots-Tag: noindex (ne pas indexer)
- X-Robots-Tag: noarchive (ne pas mettre en cache)
- X-Robots-Tag: nofollow (ne pas suivre les liens de la page)
Ces directives doivent être configurées sur votre serveur. Ainsi, si vous utilisez un serveur Apache, il faudra placer vos règles dans le fichier .htaccess. Il est également possible d’utiliser le langage PHP avec la fonction header.
Vous retrouverez l’ensemble des directives X-Robots-Tag prises en compte par Google sur cette page.
Attention, il existe quelques directives X-Robots-Tag prises en compte par Google Bot mais pas par Bing Bot, et inversement.
La gestion des balises canonical et des attributs hreflang via les entêtes HTTP
Le header HTTP peut également vous permettre de spécifier des balises canonical ou des attributs hreflang. Là encore, cela va être particulièrement utile pour les documents non HTML.
Pour rappel, la balise canonical vous permet d’indiquer qu’un document est dupliqué avec un autre, et ainsi de signaler aux moteurs de recherche lequel des deux ils doivent prendre en compte.
L’attribut Hreflang quant à lui, permet d’indiquer aux moteur de recherche les déclinaisons linguistiques d’un même document.
Démonstration avec la balise canonical
Imaginons que nous ayons une page “Test” qui est une copie de notre page d’accueil. Dans l’entête HTTP de cette page “Test”, nous pourrons mettre l’indication suivante :
Link: <https://www.orixa-media.com/>; rel="canonical"
Démonstration avec l’attribut hreflang
Imaginons maintenant que notre page d’accueil soit disponible en français et en anglais.
Dans l’entête HTTP de ces pages, nous pourrons apporter l’indication suivante :
Link: <https://www.orixa-media.com/fr/>; rel="alternate"; hreflang="fr-fr", <https://en.orixa-media.com>; rel="alternate"; hreflang="en-gb"
Vous connaissez désormais les entêtes HTTP, et l’importance de leur maîtrise pour le SEO. Vous avez besoin de l’aide d’une agence SEO pour mener à bien le référencement naturel de votre site web ? N’hésitez pas à faire appel à nos experts.